Drools规则并发问题分析&解决方案
Drools Version:6.5.0.Final
背景
Spring项目在使用Drools规则引擎做规则校验时出现并发问题,表现为加载规则文件与校验规则文件存在偏差;业务逻辑未能按照预期根据给出的规则文件进行校验。
整个修复过程划分两个阶段,本文将以两个阶段进行展示:
- 解决并发问题,但出现了内存溢出问题。具体表现为在执行规则相关逻辑一段时间后内存剧增,不能被回收
- 解决并发问题,同时解决内存溢出问题。
并发问题&内存溢出问题分析
在问题分析前对Drools相关模块进行简单描述,以便下文对源码相关部分进行解读
| 模块名称 | 作用描述 | 关键功能/特性 |
|---|---|---|
| Kie API | 提供规则引擎的核心编程接口。 | - KieServices:入口点,获取其他 Kie 组件。- KieContainer:管理规则和资源。- KieSession:规则执行的会话环境。- KieBase:存储编译后的规则。 |
| KieContainer | 规则和资源的容器,负责加载和管理规则文件。 | - 从类路径、文件系统或 Maven 仓库加载规则。 - 创建 KieBase 和 KieSession。- 支持动态更新规则(通过 KieScanner)。 |
| KieBase | 编译后的规则库,存储所有加载的规则。 | - 规则在 KieBase 中编译和优化。- 支持无状态和有状态会话。 - 可被多个 KieSession 共享。 |
| KieSession | 规则执行的运行时环境。 | - StatelessKieSession:无状态会话,适用于一次性规则执行。 - StatefulKieSession:有状态会话,适用于需要维护状态的规则执行。 - 插入事实并触发规则。 - 支持事件监听器。 |
| KieRepository | 规则资源的存储库,负责管理 KieModule。 |
- 存储和检索 KieModule。- 支持从 Maven 仓库加载规则。 |
| KieModule | 规则资源的逻辑单元,通常对应一个 Maven 模块或规则文件集合。 | - 包含规则文件、模型文件和其他资源。 - 通过 kmodule.xml 配置文件定义。 |
并发问题分析
完整的Drools执行生命周期demo
/**
* Drools生命周期
*/
public void droolsLifeCycle() {
String rulesPath = "./resource/test.drl";
KieServices kieServices = KieServices.Factory.get();
// 1. 读取规则文件
KieFileSystem kieFileSystem = kieServices.newKieFileSystem();
Path fpath = Paths.get(rulesPath);
File file = fpath.toFile();
kieFileSystem.write(ResourceFactory.newFileResource(file));
// 2. 加载drl规则文件到内存
KieBuilder kieBuilder = kieServices.newKieBuilder(kieFileSystem).buildAll();
Results results = kieBuilder.getResults();
if (results.hasMessages(Message.Level.ERROR)) {
throw new IllegalStateException("### errors ###");
}
// 3. 获取规则资源管理容器
KieContainer kieContainer = kieServices.newKieContainer(kieServices.getRepository().getDefaultReleaseId());
// 4. 获取编译后的规则库
KieBase kieBase = kieContainer.getKieBase();
// 5. 获取运行时会话
StatelessKieSession statelessKieSession = kieBase.newStatelessKieSession();
statelessKieSession.addEventListener(new DebugAgendaEventListener());
statelessKieSession.addEventListener(new DebugRuleRuntimeEventListener());
// 6. 添加被校验内容
List<Command> cmds = new ArrayList<>();
// .. 此处省略Command相关内容
// 7. 执行规则
ExecutionResults execute = statelessKieSession.execute(kieServices.getCommands().newBatchExecution(cmds));
}
1.KieFileSystem创建
KieFileSystem kieFileSystem = kieServices.newKieFileSystem();
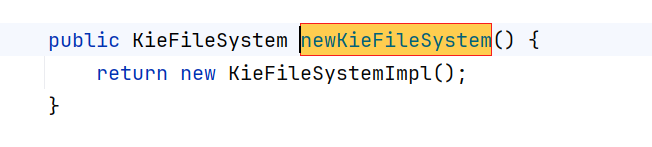
通过源码我们发现,该方法会创建一个新对象,且进行深入无公共资源使用
2.KieBuilder构建
KieBuilder kieBuilder = kieServices.newKieBuilder(kieFileSystem).buildAll();
在第一步的基础上构建KieBuilder,需要重点排查buildAll()方法。
在buildAll方法中发现了问题
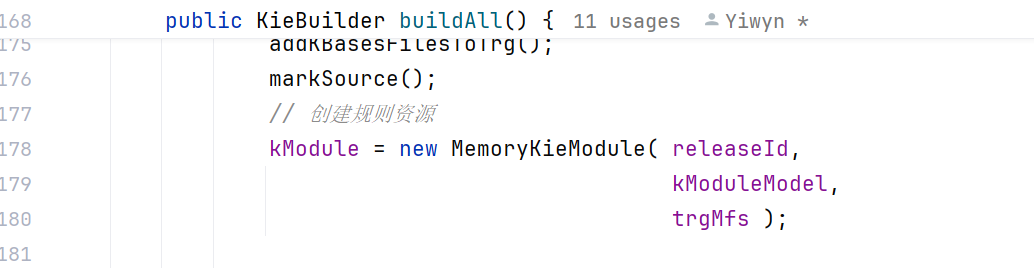
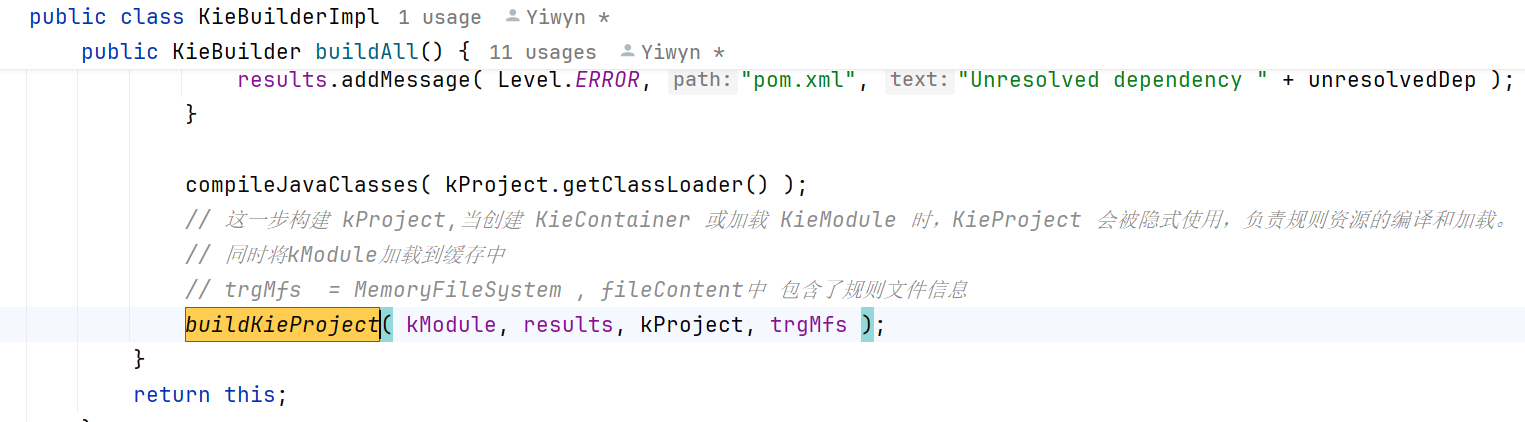
深入buildKieProject方法
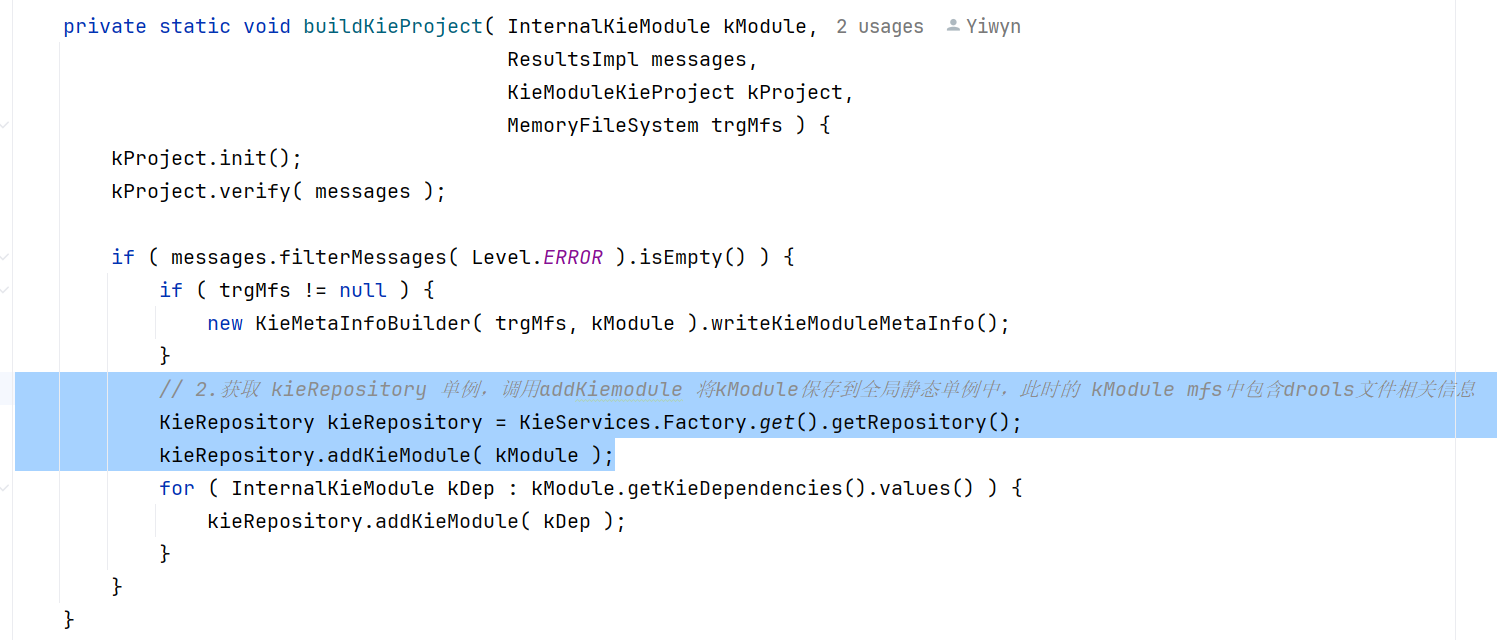
此时,携带有规则文件资源的kModule会被kieRepository添加。重点关注kieRepository和addKieModule方法。
kieRepository:KieServices.factory.get() 是一个单例;getRepository() 同样指向了一个单例,根据以下截图我们可以得出,kieRepository是一个单例并且为static类型,与此同时还会伴随一个KieModuleRepo对象的创建。 这就说明了 在我们的使用中,KieService、kieRepository、KieModuleRepo都是全局唯一的对象。继续分析addKieModule方法
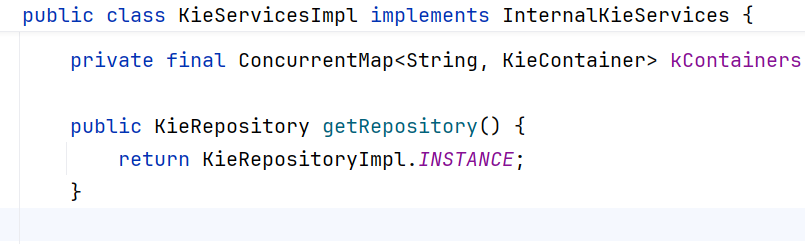


addKieModule:这里直接贴代码,我们发现了一个重点信息,在store方法中,我们貌似一直没有设置过ReleaseId,这也就意味着系统一直使用的是默认的ReleaseId,在buildAll方法中开始init()的时候,releaseId被赋予了默认值,回到store方法,我们我们发现两个LinkedHashMap kieModules和oldKieModules,
并且kieModule还是使用ga(groupId+ArtifactId)作为key,再加上我们之前一直用默认的releaseId,答案似乎很明确了,即相同的key,可能会存储不同的kieModule。 直接进行下一步。

3.获取规则资源管理容器
KieContainer kieContainer = kieServices.newKieContainer(kieServices.getRepository().getDefaultReleaseId());
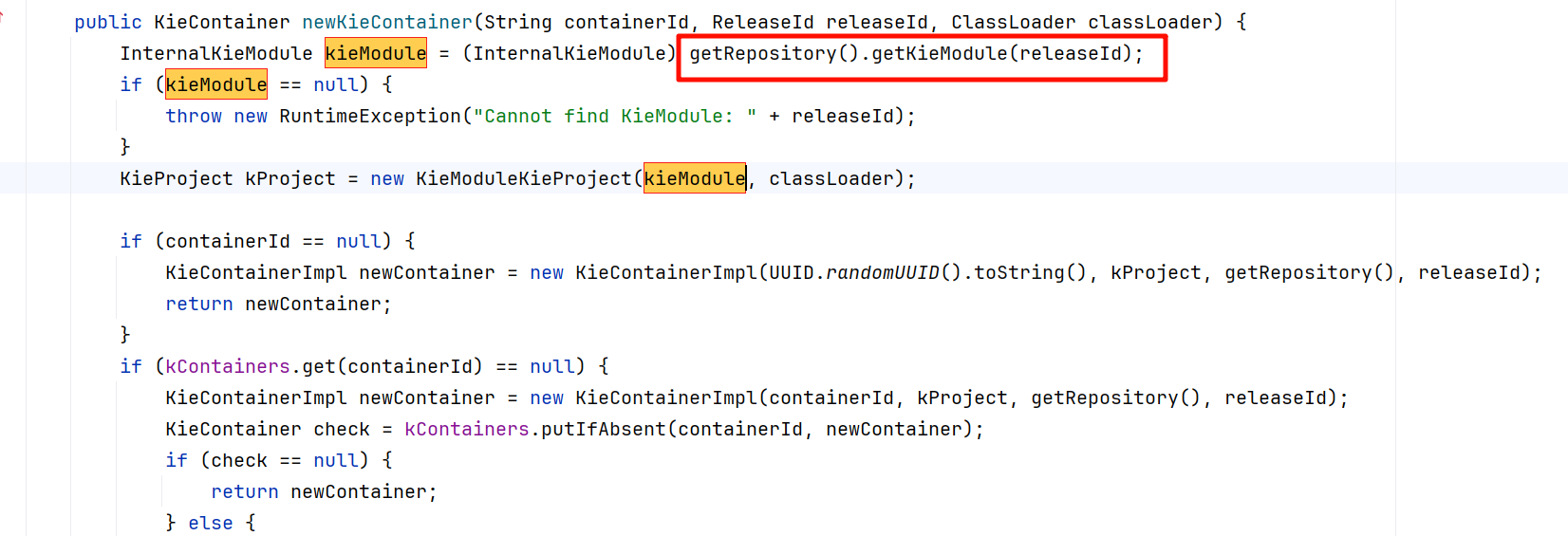
映入眼帘的就是我们再获取容器的时候,使用默认的ReleaseId进行获取,看一下源码。
在创建KieContainter的时候,系统找了 kieRepository ,在上一部我们就查明了,该对象为单例模式全局公用一个,且releaseId相同;至此并发问题的原因就找到了。
总结
在加载规则文件后,系统会使用默认的ReleaseId对kieModule进行缓存。该缓存使用LinkedHashMap,存在并发风险。
buildAll完成后,KieModuleRepo.kieModules 这个缓存中就有了DefaultReleaseId的缓存
然而如果另外一个线程此刻加载了其他的规则文件,KieModuleRepo.kieModules 中DefaultReleaseId的缓存会被覆盖为最新的
于是到了newKieContainer这一步,我们根据DefaultReleaseId获取到的缓存已经不是该方法开始加载的规则了。
// 这一步会缓存 kModule信息
KieBuilder kieBuilder = kieServices.newKieBuilder(kieFileSystem).buildAll();
// 这一步后 KieServices.Factory.get().getRepository() => KieRepositoryImpl单例
// org.drools.compiler.kie.builder.impl.KieRepositoryImpl.KieModuleRepo.kieModules 这个缓存中就有了DefaultReleaseId的缓存
Results results = kieBuilder.getResults();
// 到这一步获取 kieContainer,第一行代码 InternalKieModule kieModule = (InternalKieModule) getRepository().getKieModule(releaseId); 后面基本就不用看了
KieContainer kieContainer = kieServices.newKieContainer(kieServices.getRepository().getDefaultReleaseId());
// log.info("===========kieContainer:{}", kieContainer);
KieBase kieBase = kieContainer.getKieBase();
// log.info("===========kieBase:{}", kieBase);
解决方案
DefaultReleaseId 共有三部分,我们选择对artifactId进行加工,绑定上业务数据。这样上下文中获取的缓存将会对齐,以此避免并发问题。
这样修改之后,迎来了第二个问题,内存溢出问题,以下将详细展开
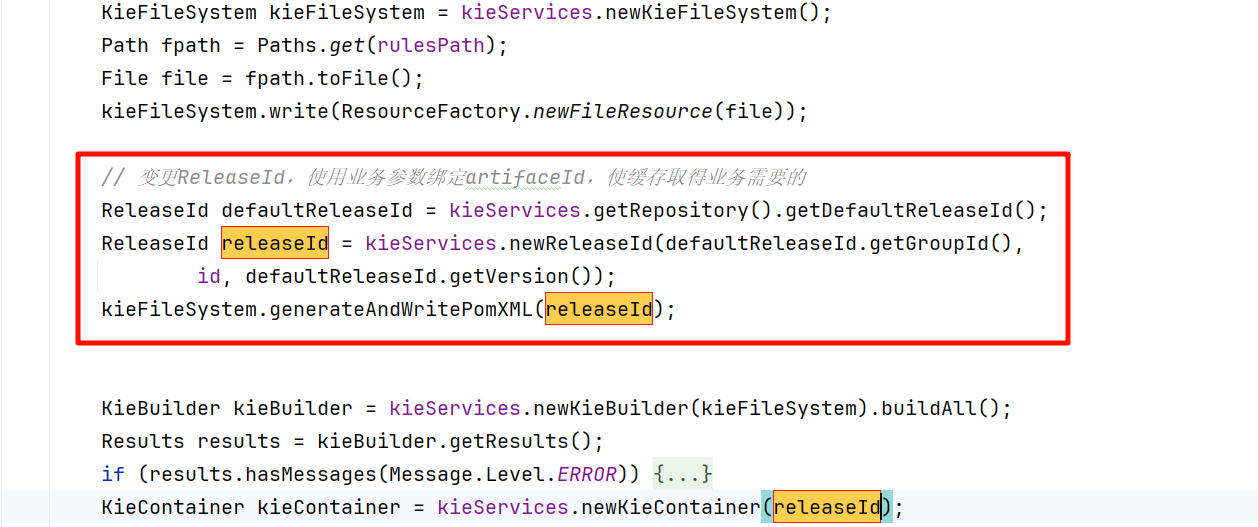
Drools规则相关组件导致系统内存溢出问题
我们在使用不同的ReleaseId进行缓存KieModule后,确实解决了并发问题。但是我们忽略了一点,由于使用了唯一的ReleaseId, kieModules和oldKieModules 会进行大量的保存,即我们加载一次规则文件,就会在kieModules添加一个缓存引用,kieModules中可是包含了规则文件本体的。
补充:
// kieModules的value信息,即相同的ga下,可能会保存不同的version
NavigableMap<ComparableVersion, KieModule>
若oldKieModules 不存在本次的releaseId key,则会取kieModules获取到的对应的key为本次ga的 NavigableMap<ComparableVersion, KieModule>,若可以渠道对应的版本,则放置在oldKieModules,具体用法本文不深入研究。
org.drools.compiler.kie.builder.impl.KieRepositoryImpl.KieModuleRepo#kieModules
org.drools.compiler.kie.builder.impl.KieRepositoryImpl.KieModuleRepo#oldKieModules
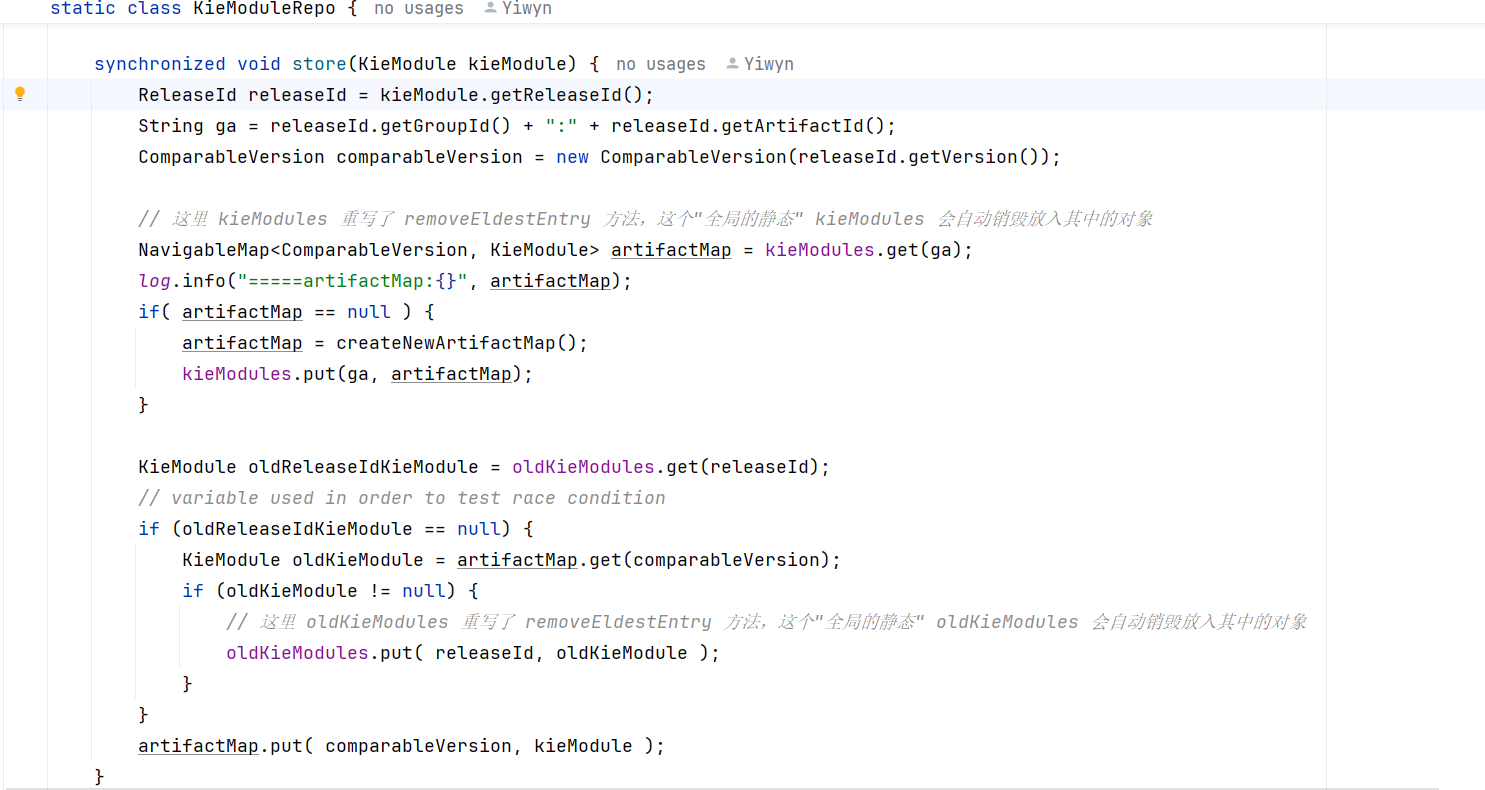
从截图中我们发现,Drools 对于两个LinkedHashMap实现了相同的重写,重写了removeEldestEntry方法【当缓存大小超过最大容量时,移除最旧的条目】,但是系统默认kieModules的缓存容量100还是非常大的。更不用提oldKieModules 的100*10缓存大小。
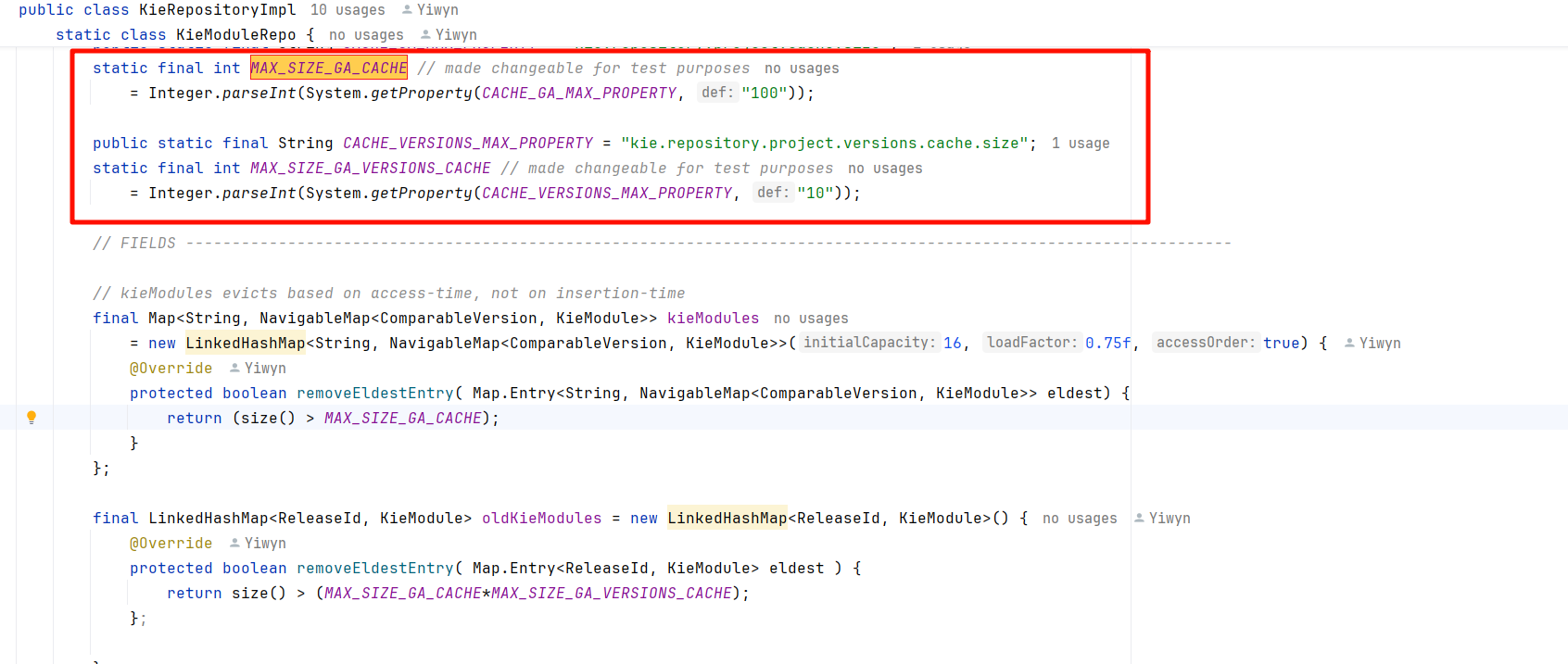
总结
KieModule本身所分配的内存相对较大,同时还需要考虑Drools其他组件对内存的占用,所以 KieRepositoryImpl.KieModuleRepo 中的缓存是内存溢出的导火索。需要针对这里进行优化。
解决方案
方案一:Drools提供了配置可以进行缓存大小的修改,但是笔者认为这里的缓存大小配置是不建议修改的,在使用了多线程处理的情况下,如果将SIZE设置的比较小,可能会出现上文将KieModle置于缓存,下文查找失败的情况。
方案二:优化artifactId粒度
举例:Y大学有计算机专业,该专业有一套针对该专业学生的Drools规则,我们大可不必将artifactId设置为学号相关,如果artifactId和学号相当则会导致数据量剧增,将来会面对成千上万的学生。这里可以将artifactId和专业号进行绑定,同时将专业的规则进行缓存。
伪代码:
// 专业的Drools规则缓存
ConcurrentHashMap<String, KieBase> ruleCache = new ConcurrentHashMap<>();
void runRule(String studentId) {
String majorId = getMajorIdByStudentId(studentId);
KieBase kieBase = ruleCache.get(majorId);
if (kieBase == null) {
kieBase = createKieBase(majorId);
ruleCache.put(majorId, kieBase);
}
StatelessKieSession session = kieBase.newStatelessKieSession();
// 执行规则
}
通过以上形式,相同的规则只需要构建一次,再得到KieBase后将其缓存,无论是并发问题,还是内存占用问题,都得到了有效的解决。同时因为缓存的组件为KieBase(可被多个 KieSession 共享), 在执行规则时无需重复KieModule构建等行为,会提高执行效率。是推荐使用的方案。
注:本文仅对Drools规则引擎的并发问题和内存溢出问题进行了分析,并提供了解决方案。实际应用中需根据具体业务场景进行调整。